
|
| análise das informações |
Business Intelligence (BI), ou Inteligência
Empresarial, define a habilidade das empresas em acessar dados e
colher informações contidas, por exemplo, em um sistema
de Data Warehouse (DW), analisando estas informações
para dar suporte às tomadas de decisões nos negócios.
O grande desafio de todo indivíduo que gerencia qualquer
processo é a análise dos fatos relacionados a seu
dever. Ela deve ser feita de modo que, com as ferramentas e dados
disponíveis, o gerente possa detectar tendências e
tomar decisões eficientes e no tempo correto. Com essa necessidade
surgiu então o conceito de Business Intelligence.
Desde a década de 70 existem produtos de BI, ainda que, na
época, não se utilizasse este termo. Nesta época,
a implantação e programação de sistemas
de bancos de dados para fins de análise tinham um custo muito
alto. Com o surgimento dos bancos de dados relacionais, dos PC's
e das interfaces gráficas como o Windows, aliados ao aumento
da complexidade dos negócios, começaram a surgir os
primeiros produtos realmente direcionados aos analistas de negócios,
qu possibilitavam rapidez e uma maior flexibilidade de análise.
Há milhares de anos atrás, Fenícios, Persas,
Egípcios e outros Orientais já faziam, a seu modo,
Business Intelligence, ou seja, cruzavam informações
provenientes da natureza, tais como comportamento das marés,
períodos de seca e de chuvas, posição dos astros,
para tomar decisões que permitissem a melhoria de vida de
suas comunidades.
O termo BI surgiu na década de 80, cunhado pelo Gartner Group,
e tem como principais características:
 Extrair
e integrar dados de múltiplas fontes Extrair
e integrar dados de múltiplas fontes
Fazer
uso da experiência
Analisar
dados contextualizados
Trabalhar
com hipóteses
Procurar
relações de causa e efeito
Transformar
os registros obtidos em informação útil para
o conhecimento empresarial
São ferramentas de Business Intelligence:
Data
Warehouses
Planilhas Eletrônicas
Geradores de Consultas e Relatórios
EIS
Data
Marts
Data Mining
Ferramentas
OLAP
|
| Data Warehouse |
Segundo W.H.Inmon (um dos "pais" dos conceitos
de DW), um data warehouse é uma coleção de
dados orientada por assuntos, integrada, variante no tempo, e não
volátil, que tem por objetivo dar suporte aos processos de
tomada de decisão.
Podemos dizer também que o data warehouse é um conjunto
de tabelas (banco de dados) contendo dados extraídos dos
sistemas de operação da empresa (ERPs, tarifadores,
etc.), tendo sido otimizados para processamento de consulta e não
para processamento de transações.
Em geral, um data warehouse requer a consolidação
de outros recursos de dados além dos armazenados em BDs relacionais,
incluindo informações provenientes de planilhas eletrônicas,
documentos textuais, etc. O objetivo de um data warehouse é
fornecer uma imagem única da realidade do negócio.
De uma forma geral, sistemas de data warehouse compreendem um conjuntos
de programas que extraem dados do ambiente de dados operacionais
da empresa, um banco de dados que os mantém, e sistemas que
fornecem estes dados aos seus usuários.
Pode-se dizer que sistemas de data Warehouse revitalizam os sistemas
da empresa, porque:
permitem
que sistemas mais antigos continuem em operação;
consolidam dados inconsistentes
dos sistemas mais antigos em conjuntos coerentes;
extraem
benefícios de novas informações oriundas das
operações correntes;
provêm
ambiente para o planejamento e arquitetura de novos sistemas de
cunho operacional.
Como se vê, existem diferentes visões do que seria
um data warehouse: uma arquitetura, um conjunto de dados semanticamente
consistente com o objetivo de atender diferentes necessidades de
acesso a dados e extração de relatórios, ou
ainda, um processo em constante evolução, que utiliza
dados de diversas fontes heterogêneas para dar suporte a consultas
ad-hoc, relatórios analíticos e à tomada de
decisão.
É importante considerar, no entanto,
que um data warehouse não contem apenas dados resumidos,
podendo conter também dados primitivos. É desejável
prover ao usuário a capacidade de aprofundar-se num determinado
tópico, investigando níveis de agregação
menores ou mesmo o dado primitivo, permitindo também a geração
de novas agregações ou correlações com
outras variáveis. Além do mais, é extremamente
difícil prever todos os possíveis dados resumidos
que serão necessários: limitar
o conteúdo de um data warehouse apenas a dados resumidos
significa limitar os usuários apenas às consultas
e análises que eles puderem antecipar frente a seus requisitos
atuais, não deixando qualquer flexibilidade para novas necessidades.
|
| Data Mart |
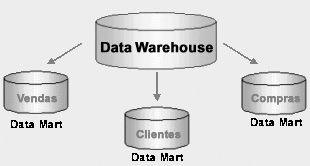
O Data Mart, também conhecido como Warehouse
Departamental, é uma abordagem descentralizada do
conceito de Data Warehouse. Como os projetos sobre Data Warehouse
(DW) referiam-se a uma arquitetura centralizada, sua implementação
não é uma tarefa fácil, embora fosse interessante
as características de uniformidade, controle e segurança.
A implementação de um DW completo requer uma metodologia
rigorosa e uma completa compreensão dos negócios da
empresa. Esta abordagem pode ser longa e dispendiosa e por isto
sua implementação exige um planejamento bem detalhado
(em
outras palavras: tempo longo). Neste contexto e com a necessidade
de agilização de implantação dos projetos
de DW, o Data Mart passou a ser uma opção de arquitetura
interessante.
Existem duas maneiras de distintas de criação de data
marts: top-down e botton-up.
Top-down: é quando a empresa cria um DW e depois parte para
a segmentação, ou seja, divide o DW em áreas
menores gerando assim pequenos bancos orientados por assuntos departamentalizados.
Botton-up: é quando a situação é inversa.
A empresa por desconhecer a tecnologia, prefere primeiro criar um
banco de dados para somente uma área. Com isso os custos
são bem inferiores de um projeto de DW completo. A partir
da visualização dos primeiros resultados parte para
outra área e assim sucessivamente até resultar num
Data Warehouse completo.
|
|
A tecnologia usada tanto no DW como no Data Mart é a mesma,
as variações que ocorrem são mínimas,
sendo em volume de dados e na complexidade de carga. A principal
diferença é a de que os Data Marts são voltados
somente para uma determinada área, já o DW é
voltado para os assuntos da empresa toda.
Portanto, cabe a cada empresa avaliar a sua demanda e optar pela
melhor solução. O maior atrativo para implementar
um data Mart é o seu custo e prazo. Segundo estimativas,
um Data Mart custa de 5 a 50% do custo total de um DW integral e
seu prazo de implantação é de cerca de 120
dias enquanto que o DW integral leva cerca de um ano para estar
consolidado.
|
| Metadados |
Os metadados são definidos como dados dos
dados, informações das informações.
Dada a complexidade das informações de um Data Warehouse,
a documentação dos sistemas e dos bancos de dados
tornou-se de vital importância. Este tipo de registro já
era tido como muito importante desde o surgimento dos primeiros
bancos de dados. Com o DW, isto se tornou fundamental, pois
sendo um projeto gigantesco, se não houver uma documentação
eficiente, ninguém conseguirá entender mais nada.
Num projeto de DW, deve-se gerar documentação sobre
o levantamento de dados, do banco de dados, relatórios a
serem gerados, origem dos dados que alimentam o DW, processos de
extração, tratamento e rotinas de carga dos dados,
além de, possivelmente, regras de negócio da empresa
e todas suas mudanças.
Segundo Inmon (um dos "papas" dos conceitos de DW), os
metadados englobam o DW e mantém as informações
sobre o que está onde. O autor ainda define quais informações
os metadados mantém:
A
estrutura dos dados segundo a visão do programador;
A
estrutura dos dados segundo a visão dos analista de SAD;
A fonte de dados que alimenta o
DW;
A transformação
sofrida pelos dados no momento de sua migração para
o DW;
O modelo de dados;
O relacionamento entre o modelo
de dados e o DW;
O histórico
das extrações de dados;
Os dados referentes aos relatórios que são gerados
pelas ferramentas OLAP assim como os que são gerados nas
camadas semânticas.
Os metadados podem surgir de vários locais durante o decorrer
do projeto. Desde o material originado das entrevistas com os usuários
até documentação dos sistemas operacionais.
Aliás, as entrevistas muitas vezes tornam-se uma fonte preciosa
de informações, pois muitos dados levantados não
estão (e não estariam) documentados em nenhum outro
lugar. Nesta fase, deve-se definir, inclusive, as regras para validação
dos dados após carregados no DW.
Como pudemos ver, o volume de metadados gerados é muito grande.
Existem hoje algumas ferramentas que fazem única e exclusivamente
o gerenciamento dos metadados. Elas têm algumas características
peculiares. Essas ferramentas conseguem mapear o dado em todas as
etapas de
desenvolvimento do projeto, desde a conceitual até a de visualização
dos dados em ferramentas OLAP/EIS.
A regra da boa implementação de um projeto de DW reza
que devemos sempre nos preocupar com os metadados, pois são
eles que servirão de guia por entre as brumas das tabelas,
relatórios e dados quando estivermos perdidos.
|
| ETL (extration, tranform and load) |
A etapa de ETL é uma das mais críticas
de um projeto de DW, pois uma informação carregada
erroneamente trará conseqüências imprevisíveis
nas fases posteriores. O objetivo desta fase é fazer a integração
de informações de fontes múltiplas e complexas.
Basicamente, divide-se esta etapa em três passos: extração,
transformação e carga dos dados. Embora tenhamos hoje
em dia ferramentas
que auxiliam na execução do trabalho, ainda assim
é um processo trabalhoso, complexo e também muito
detalhado.
Carga. Num processo de ETL, primeiramente devemos definir as origens
das fontes de dados e fazer a
extração deles. As origens deles podem ser várias
e também em diferentes formatos, onde poderemos encontrar
desde os sistemas transacionais das empresas (por exemplo: SAP,
BSCS, etc.) até planilhas, arquivos textos e também
arquivos DBF (dBase) ou do Microsoft Access.
Limpeza. Definidas as fontes, partimos para o segundo passo que
consiste em transformar e limpar esses dados. A limpeza é
necessária porque os dados normalmente advém de uma
fonte muitas vezes desconhecida nossa, concebida há muito
tempo, contendo muito lixo e inconsistência. Por exemplo:
se a empresa for de cartão de crédito, o vendedor
está mais preocupado em vender o produto (cartão)
do que na qualidade de dados que está inserindo. Se o cliente
não tiver o número do RG na hora da venda, o vendedor
cadastrará um número qualquer para agilizar a venda.
Se for feita uma consulta posterior, levando-se em conta o número
do RG dos clientes, no mínimo informações estranhas
aparecerão (algo como RG número 99999999-99). Por
isso, nessa fase do DW, faz-se a limpeza desses dados, para haver
compatibilidade entre eles.
Transformação. Uma vez que a origem dos dados podem
ser de sistemas diferentes, às vezes é necessário
padronizar os diferentes formatos. Por exemplo: em alguns sistemas
a informação sobre o sexo do cliente pode estar armazenada
no seguinte formato : “M” para Masculino e “F”
para Feminino. Porém, em algum outro sistema pode estar guardadado
como “H” para Masculino e “M” para Feminino
e assim sucessivamente. Quando levamos esses dados para o DW, deve-se
ter uma padronização deles, ou seja, quando o usuário
for consultar o DW, ele não pode ver informações
iguais em formatos diferentes. Portanto, fazemos o processo de ETL,
transformamos esses dados e deixamos num formato uniforme normalmente
sugerido pelo próprio usuário. No DW, teremos somente
M e F, fato esse que facilitará a análise dos dados
que serão recuperados pela ferramenta OLAP.
Apesar de existirem ferramentas de ETL como o Data Stage (Ardent/Informix),
o DTS (Microsoft) e o Sagent (da própria Sagent), às
vezes é necessário criar rotinas de carga para atender
determinadas situações que poderão ocorrer.
Todos tem os seus diferenciais e cada um poderá ser utilizado
dependendo do caso de cada empresa. O mais importante é que
uma ferramenta de ETL tem grande valia, principalmente se os sistemas
OLTP (transacionais) são muitos, pois elas são uma
poderosa fonte de geração de metadados, e que contribuirão
muito para a produtividade da equipe.
|
| Data Mining |
Data Mining (ou mineração de dados)
utiliza técnicas estatísticas e de aprendizado de
máquinas (redes
neurais) para construir modelos capazes de predizer o comportamento
de clientes. Hoje em dia, a tecnologia consegue automatizar o processo
de mineração, integrá-lo ao data warehouse
e apresentá-lo de forma relevante aos seus usuários.
O Data mining é a descoberta de conhecimento interessante,
mas escondido em grandes bases de dados. Bases de dados corporativas
freqüentemente contêm tendências desconhecidas,
relações entre objetos, como clientes e produtos,
que são de importância estratégica para a organização.
Diferentes técnicas existem para analisar os dados dos clientes.
Há técnicas convencionais, como OLAP,
ferramentas de consulta (query) e estatística, e novas técnicas
como data mining. O valor de data mining pode ser melhor compreendido
se comparado a técnicas convencionais. O data mining difere
de técnicas estatísticas porque, ao invés de
verificar padrões hipotéticos, utiliza os próprios
dados para descobrir tais padrões.
Bases de dados armazenam conhecimento que podem nos auxiliar a melhorar
nossos negócios. Técnicas tradicionais permitem a
verificação de hipóteses. Aproximadamente 5%
de todas as relações podem ser encontradas por este
método. Data mining pode descobrir outras relações
anteriormente desconhecidas: os 95% restantes. Em outras palavras,
você pode dizer que técnicas convendionais "falam"
à base de dados, enquanto data mining "ouve" a
base de dados. Se você não fizer uma pergunta específica,
nunca terá a resposta. Data mining explora as bases de dados
através de dezenas de centenas de pontos de vista diferentes.
Toda a informação escondida relacionada ao comportamento
dos clientes será mapeada e enfatizada.
Data mining não substitui técnicas estatísticas
tradicionais. Ao invés disto, data mining é uma extensão
dos métodos estatísticos, que são em parte
o resultado de uma mudança maior na comunidade de estatística.
O poder cada vez maior dos computadores com custos mais baixos,
aliado à necessidade de análise de enormes conjuntos
de dados com milhões de linhas, permitiu o desenvolvimento
de técnicas baseadas na exploração de soluções
possíveis pela força bruta.
O ponto chave é que data mining é a aplicação
desta e de outras técnicas de IA e estatística de
problemas relacionados a negócios, de forma a tornar estas
técnicas disponíveis tanto a estatísticos como
a usuários de mercado.
Muitas técnicas de datamining foram desenvolvidas no passado
para extrair informações de dados. Ou seja, data mining
é a combinação de diferentes técnicas
de sucesso comprovado, como inteligência artificial, estatística
e bancos de dados.
Em resumo, o uso de data mining para construção de
um modelo traz as seguintes vantagens.
Modelos
são de fácil compreensão: pessoas sem conhecimeno
estatístico (por exemplo, analistas
financeiros ou pessoas que trabalham com database marketing) podem
interpretar o modelo e compará-lo com suas próprias
idéias. O usuário ganha mais conhecimento sobre o
comportamento do cliente e pode usar esta informação
para otimizar os processos dos negócios.
Grandes
bases de dados podem ser analisadas: grandes conjuntos de dados,
de até vários gigabytes de informação
podem ser analisados com data mining. Por exemplo, para cada um
dos seus clientes, você pode ter centenas de atributos que
contêm informações detalhadas. Bases de dados
podem ser muito extensas também: você pode querer mineirar
uma base de dados contendo milhões de registros de clientes.
Data mining descobre informações
que você não esperava: como muitos modelos diferentes
são validados, alguns resultados inesperados podem surgir.
Em diversos estudos, descobriu-se que combinações
de fatores particulares tiveram resultados inesperados. Estes gérmens
de conhecimento escondido (hidden nuggets) provaram ter valor competitivo
para os negócios em questão.
Variáveis
não necessitam de recodificação: data mining
lida tanto com variáveis numéricas quanto categóricas.
Estas variáveis aparecem no modelo exatamente da mesma forma
em que aparecem na base de dados.
Modelos
são precisos: os modelos obtidos por data mining são
validados por técnicas de estatística. Desta forma,
as predições feitas por estes modelos são precisas.
Modelos são construídos
rapidamente: data mining permite gerar modelos atualizados em poucos
minutos, ou poucas horas. A modelagem se torna mais fácil
já que os modelos são testados, e apenas os melhores
modelos são retornados aos usuários.
|
| OLAP |
O OLAP proporciona as condições de
análise de dados on-line necessárias para responder
às possíveis
torrentes de perguntas dos analistas, gerentes e executivos. OLAP
é implementado em um modo de
cliente/servidor e oferece respostas rápidas as consultas,
criando um microcubo na máquina cliente ou no servidor.
As ferramentas OLAP são as aplicações que os
usuários finais têm acesso para extraírem os
dados de suas bases e construir os relatórios capazes de
responder a suas questões gerenciais. Elas surgiram juntamente
com os sistemas de apoio a decisão para fazerem a consulta
e análise dos dados contidos nos Data Warehouses e Data Marts.
A funcionalidade de uma ferramenta OLAP é caracterizada pela
análise multi-dimensional dinâmica dos dados, apoiando
o usuário final nas suas atividades, tais como: Slice and
Dice e Drill.
Vamos ver algumas características dessas ferramentas:
Consultas ad-hoc: segundo Inmon, são consultas com acesso
casual único e tratamento dos dados segundo parâmetros
nunca antes utilizados, geralmente executado de forma iterativa
e heurística. Em outras palavras, a possibilidade do próprio
usuário gerar consultas de acordo com suas necessidades de
cruzar as informações de uma forma não vista
e com métodos que o levem a descoberta daquilo que procura.
Slice-and-Dice: é a técnica que permite analisar as
informações de diferentes prismas limitados somente
pela nossa imaginação. Utilizando esta tecnologia
consegue-se ver a informação sobre ângulos que
anteriormente inexistiam sem a confecção de um DW
e a utilização de uma ferramenta OLAP.
Drill Down/Up: consiste em fazer uma exploração em
diferentes níveis de detalhe das informações.
Com o Drill Down você pode “subir ou descer” dentro
do detalhamento do dado, como por exemplo analisar uma informação
tanto diariamente quanto anualmente, partindo da mesma base de dados.
Geração de Queries: a geração de queryes
no OLAP se dá de uma maneira simples, amigável e transparente
para o usuário final, o qual precisa ter um conhecimento
mínimo de informática para obter as informações
que deseja.
Cada uma destas tecnologias e técnicas tem seu lugar e são
complementares entre si, pois dão apoio a diferentes tipos
de análises. É importante lembrar que as exigências
do usuário devem ditar que tipo de Data Mart você está
construindo. Como sempre, a tecnologia e técnicas devem estar
bem fundamentadas para atenderem da melhor maneira possível
essas exigências.
Os Data Warehouses/Data Marts, servem como fonte de dados para estas
aplicações, assegurando a consistência, integração
e precisão dos dados. Os sistemas transacionais não
conseguem responder essas questões por isso, é necessária
a criação de um ambiente de apoio de decisão
robusto, sustentável e confiável. |
|